Pyspark How to Read From Oracle Db
Spark and Oracle Database
Ease of structured data and efficiency of Spark
![]()
Shilpa has become an adept in Spark and enjoys Big data analysis. Everything was going well until her employer wanted to know the kind of insight they tin can get by combining their enterprise information from the Oracle database with Large Information.
Oracle database is the most sold enterprise database. Most of the enterprise applications, like ERP, SCM applications, are running on the Oracle database. Like Shilpa, most of the data scientists come up across situations where they have to relate the information coming from enterprise databases like Oracle with the data coming from a Big Information source like Hadoop.
Thursday e re are two approaches to accost such requirements:
- Bring the enterprise data into the Big Data storage organisation similar Hadoop HDFS and then access it through Spark SQL.

This arroyo has the post-obit drawbacks:
- Data duplication
- Enterprise data has to be brought into Hadoop HDFS. This requires a information integration solution and will mostly be a batch operation, bringing in information latency issues.
two. Keep the operational enterprise information in the Oracle database and Big Data in Hadoop HDFS and access both through Spark SQL.

- Only the required enterprise data is accessed through Spark SQL.
- If required the enterprise data tin can be stored in Hadoop HDFS through Spark RDD.
I am elaborating on the 2d arroyo in this article. Let's become through the basics first.
Spark
If you lot want to know almost Spark and seek step-past-stride instructions on how to download and install information technology along with Python, I highly recommend my below article.
Oracle Database
If you desire to know about the Oracle database and seek step-past-pace instructions on how to install a fully functional server-class Oracle database, I highly recommend my below article.
JDBC
Before nosotros taking a deeper swoop into Spark and Oracle database integration, one shall know virtually Java Database Connection (JDBC).
A Java application can connect to the Oracle database through JDBC, which is a Java-based API. As Spark runs in a Java Virtual Machine (JVM), it tin can be connected to the Oracle database through JDBC.
Y'all tin can download the latest JDBC jar file from the below link
You should get the ojdbc7.jar file. Save this file into the …/spark/jars folder, where all other spark system class files are stored.

Connecting Spark with Oracle Database
Now that you already have installed the JDBC jar file where Spark is installed, and you lot know access details (host, port, sid, login, password) to the Oracle database, let's begin the activeness.
I have installed Oracle Database also as Spark (in local mode) on AWS EC2 instance as explained in the above commodity.
- I can access my oracle database sanrusha. The database is up and running.

2. Database listener is likewise upwardly and running
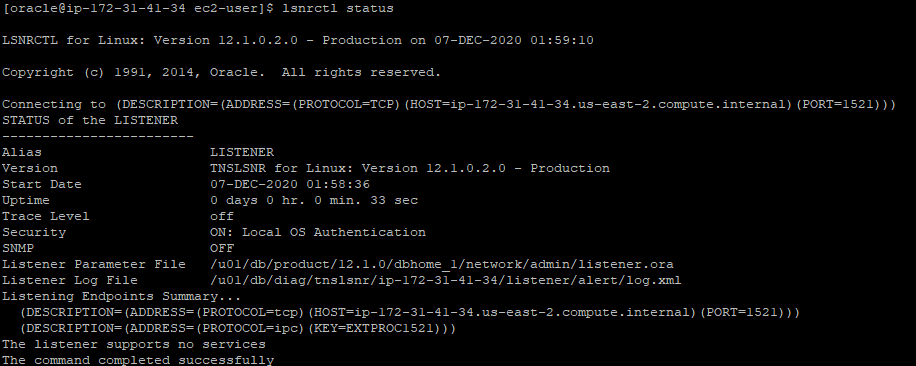
three. Database user is sparkuser1. This user has access to i table test, that has merely on column A, simply no data.

In the next footstep, going to connect to this database and table through Spark.
4a. Log in to the Spark automobile and get-go Spark through Spark-shell or pyspark.

4b. Below control creates a spark dataframe df with details of the Oracle database table examination. Write this control on Scala prompt.
val df= spark.read.format("jdbc").selection("url","jdbc:oracle:thin:sparkuser1/oracle@<oracledbhost>:<oracle db access port default is 1521>/<oracledbsid>").option("dbtable","exam").option("user","sparkuser1").selection("password","oracle").option("driver","oracle.jdbc.driver.OracleDriver").load() 4c. df.schema will show the details of the tabular array. In this case, it is a uncomplicated test tabular array with merely one column A.

4d. Open a browser, enter the beneath address
http://<public IP address of automobile where Spark is running>:4040
Click on the SQL tab. You should see the details like what time the connectedness request was submitted, how long connection and information retrieval activities took, and also the JDBC details.

Spark can also exist initiated through a Spark session.builder API available in Python. Open up Jypyter notebook and enter the below details to beginning the Spark application session and connect information technology with the Oracle database
Here is a snapshot of my Jupyter notebook.

Conclusion
This was a modest article explaining options when it comes to using Spark with Oracle database. You tin extend this noesis for connecting Spark with MySQL and databases.
Looking forward to your feedback.
Reference:
Apache Spark for Information Engineers
Source: https://towardsdatascience.com/spark-and-oracle-database-6624abd2b632
0 Response to "Pyspark How to Read From Oracle Db"
Postar um comentário